Development of Voice Synthesis Systems with Emphasis on Prosody
Research project on developing multilingual automatic dubbing systems preserving human-like prosodic characteristics.
Project Overview
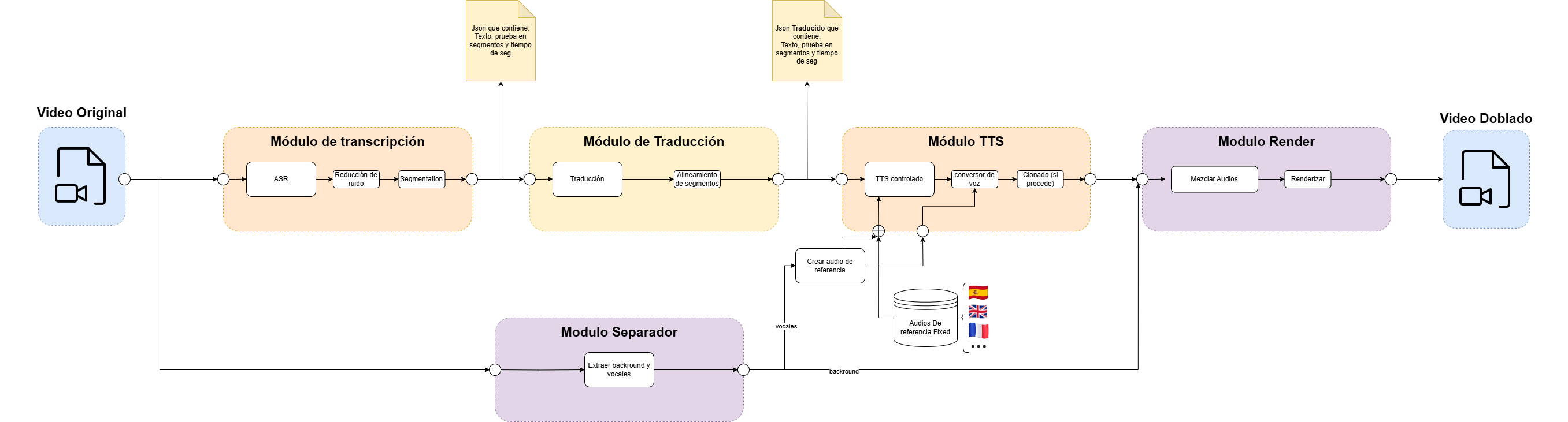
This project emerged from an internship at ETIQMEDIA's R&D department, aiming to create a multilingual automatic dubbing system emphasizing natural prosody. Leveraging neural networks for voice synthesis, the project achieved precise synchronization between dubbed audio and original video, delivering human-like voice quality.
System Architecture
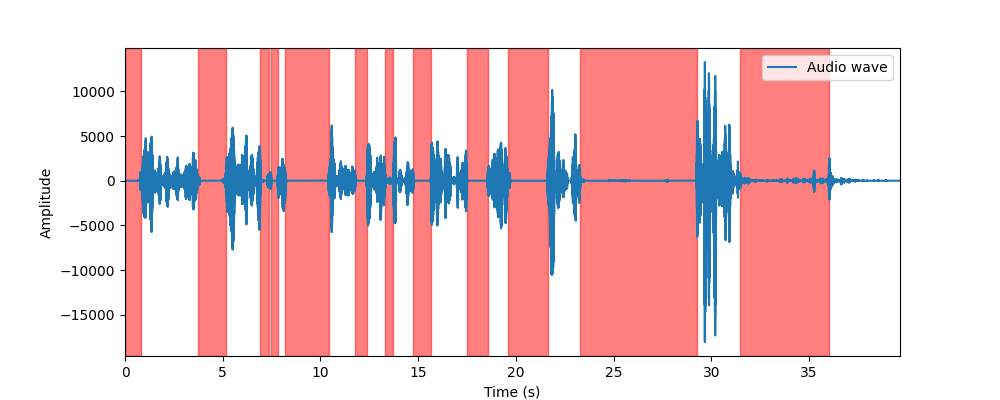
Signal Processing
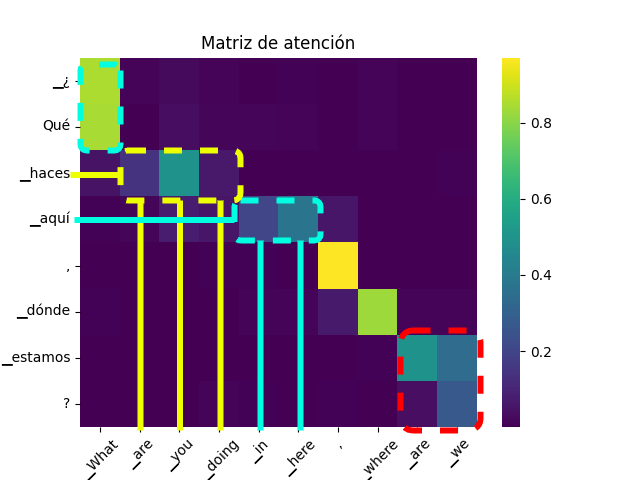
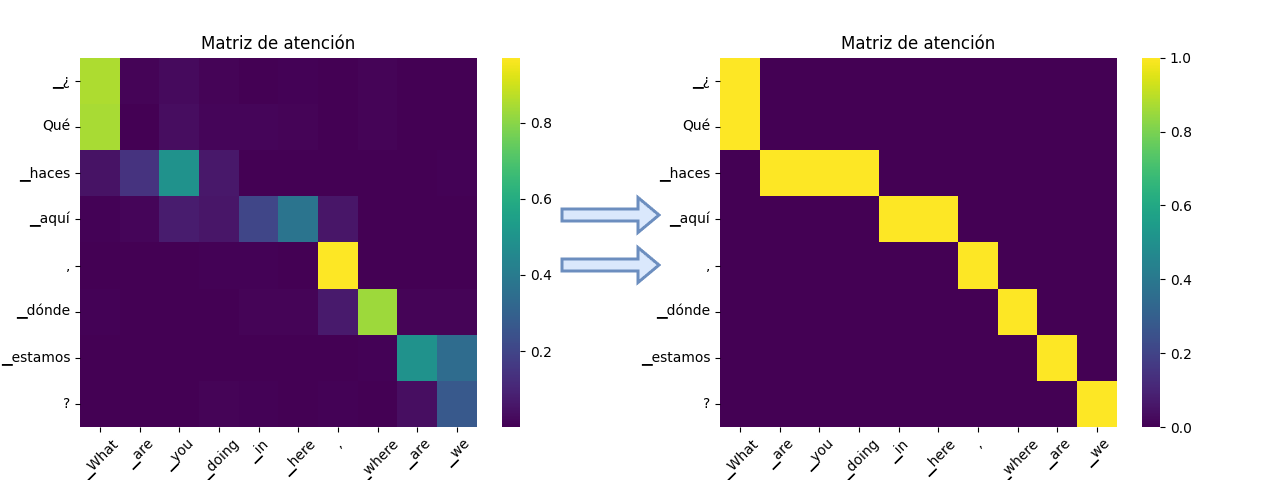
Attention Mechanisms
Key Features
- Accurate transcription using Whisper (OpenAI)
- High-quality translations with OPUS MT models
- Voice synthesis with XTTS v2, ensuring human-like prosody
- Advanced audio processing and speaker style transfer
- Modular design for easy maintenance and scalability
Performance Metrics
- Whisper Transcription (WER): 9.6% Spanish, 7.6% English
- Translation Quality (BLEU): Average score of 58
- Voice naturalness and synchronization validated through subjective testing
Future Improvements
- Advanced language models for improved translation and dubbing coherence
- Lip synchronization techniques implementation
- Graphical interfaces for manual dubbing correction and editing
Project Details
Technologies
Python PyTorch OpenAI Whisper Transformers XTTS v2 CUDA
Evaluation Metrics
BLEU WER